«Урожайность увеличилась на 13%». Как ИИ научили выращивать грибы в Беларуси

Искусственный интеллект набирает сегодня огромную популярность. Но, к сожалению для бизнеса, он проникает больше в общественную жизнь (генерация мемов и аватарок в соцсети), немного в маркетинг (создание креатива и рекламы), продажи (чатботы, ии-консультаны, виртуальные помощники) и не так интенсивно в реальный сектор экономики. Но есть уже и такие успешные кейсы. Директор ООО «БТВ-Агро» (завода, который занимается выпуском грибниц для выращивания шампиньонов) Роман Дубинка поделился с «Про бизнес» опытом, неудачами, успехами и уроками использования ИИ для решения реальной производственной задачи, причем без привлечения профессиональной команды разработчиков.

Директор ООО «БТВ-Агро»
«Мы не были готовы мириться с тем, что наш компост дает урожайность хуже, чем у конкурентов»
— Наш завод занимается выпуском грибниц для выращивания шампиньонов всего 3 года, и как любая молодая компания мы сталкивались с разными проблемами и вызовами: поломки оборудования, дефицит персонала, отсутствие регламентов, нарушение технологии. Но главной задачей оставалось повышение качества компоста и его урожайности. Каждый клиент хотел получать больше гриба с каждой тонны полученного компоста, и мы понимали, что их запрос абсолютно справедлив. Мы не были готовы мириться с тем, что наш компост дает урожайность хуже, чем у конкурентов.
Сперва мы обратились за помощью к консультантам и партнерам, но сложность заключалась в том, что производство компоста, как и выращивание грибов, слишком сложный и многофакторный процесс, где изменение всего одного параметра влияет на всю систему и конечный результат. Посещали разные заводы и поняли: если что-то работает у одной компании и дает результат, то не всегда точно так же работает в другой — опять же по причине многофакторности. Разное сырье, оборудование, технология, процессы и даже погода — каждая переменная лишь добавляет непредсказуемости. Не найдя ответов на свой вопрос во внешней среде, мы вернулись к поискам на нашем производстве.
Первое что мы сделали — обратились к классическим инструментам статистики: корреляционный и регрессионный анализ. У нас в распоряжении были базовые результаты лабораторных анализов (уровень азота органического, уровень азота общего, кислотность, зольность, влажность, соотношение углерода к азоту). При помощи стандартных инструментов и функций Excel мы попробовали найти зависимость между результатами анализов и урожайностью.
Наши данные на тот момент представляли собой матрицу, состоящую из всего 300 строк (партий) и 8 столбцов (значений лабораторных анализов и урожайности). Но какие бы мы параметры и комбинации не использовали, нам не удавалось получить R2 (коэффициент множественной детерминации) более 15%. Это достаточно низкий показатель, который говорит об очень слабой зависимости урожайности от наших параметров.
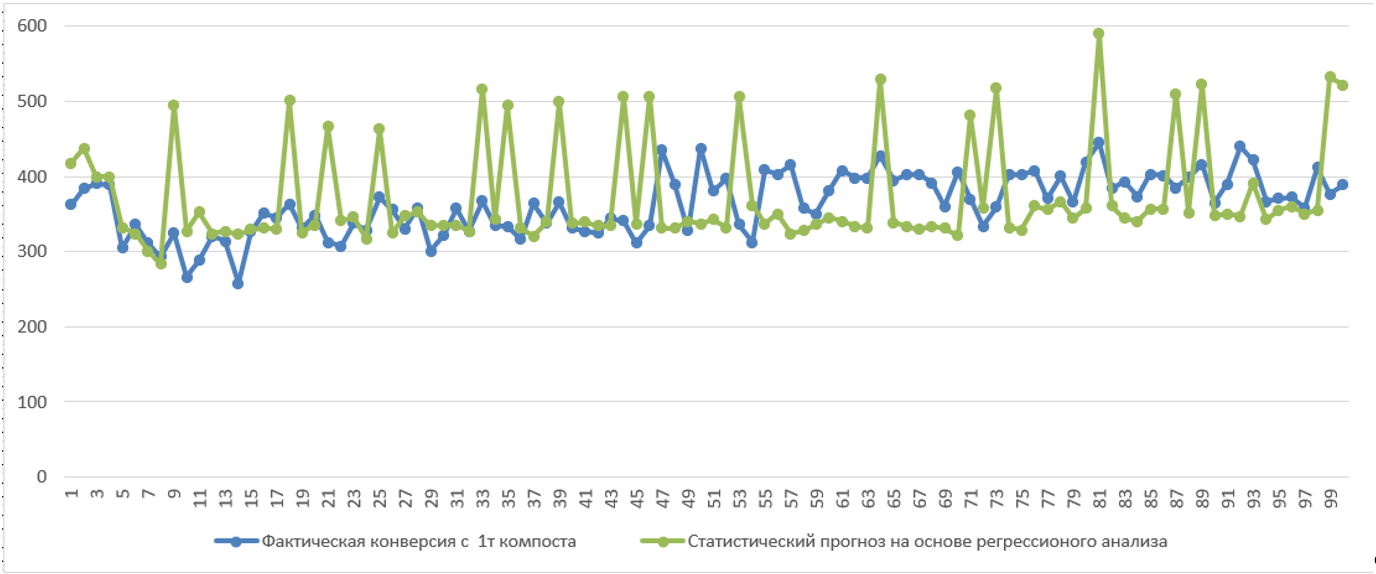
Поэтому мы посмотрели в нашей учетной ERP-системе, какими еще данными мы можем дополнить модель и нашли 4 дополнительных параметра, которые, по-нашему мнению, могли влиять на результат (расход соевой добавки на тонну компоста, расход мицелия на тонну компоста, масса азота на тонну соломы, масса азота на сухое вещество). Коэффициент детерминации подрос до 40%, но этого было по-прежнему недостаточно. Тогда мы обратились за помощью к нашим клиентам и попросили их дополнить наши данные своими, т.к. в грибном бизнесе очень многое зависит от того, как клиент работает с компостом: сколько выкладывает на квадратный метр, как поливает, какую температуру поддерживает, как завязывает гриб и как его собирает.
Благодаря клиентским данным (масса загруженного компоста в камеру, масса загруженного торфа, количество волн) R2 подрос до 76%, что уже внушало здоровый оптимизм. Теперь мы могли неплохо предсказывать, какую урожайность ожидать с нашего компоста и какое его оптимальное количество необходимо клиентам загрузить в камеру, чтобы максимизировать урожайность. Но нам все еще было интересно почему R2 =76, а не 100%, что мы еще не учли или не видим?

«Мы провели 2 дня в тесном общении с нейросетями»
Чуть больше года назад каждый продвинутый пользователь интернета начал общаться сначала с ChatGPT, а потом и с более доступным (бесплатным) AI-чатом DeepSeek. Мы первое время также использовали различные AI ассистенты: преимущественно для написания внутренних регламентов или писем клиентам, т.к. на глубокий анализ они еще не были способны. С выходом новых версий становилось понятно, что теперь они могут решать и более сложные задачи.
Именно тогда мы и попытались загрузить в AI-ассистент наши данные и попросить проанализировать, на что получили ответ, что такого он сделать не может (сегодня уже может), но выдал подробную инструкцию, как это можно реализовать, самостоятельно используя среду разработки Anaconda и язык Python. Вся разработка сводилась к тому, чтобы спрашивать у разных ИИ-чатов: какой следующий шаг или почему алгоритм не работает, а выдает ошибку? Мы провели 2 дня в тесном общении с ChatGPT, DeepSeek, Grok, Qwen и по их инструкциям установили необходимое программное обеспечение (Anaconda, Jupyter, Python), а затем создали сразу несколько разных моделей, которые давали немного разную точность предсказания: линейная регрессия, дерево решений, RandomForest, Gradient Boosting, MLPRegressor.

Разобравшись с настройками параметров и подобрав оптимальные, нам удалось на алгоритме, использующем модель RandomForest, повысить качество предсказания до 87% на тех же самых данных. ИИ модель увидела связи и зависимости, которые обычная статистика увидеть не могла. Этого уровня было вполне достаточно, чтобы мы смогли определить оптимальные комбинации параметров качества компоста, дающего максимальный результат.
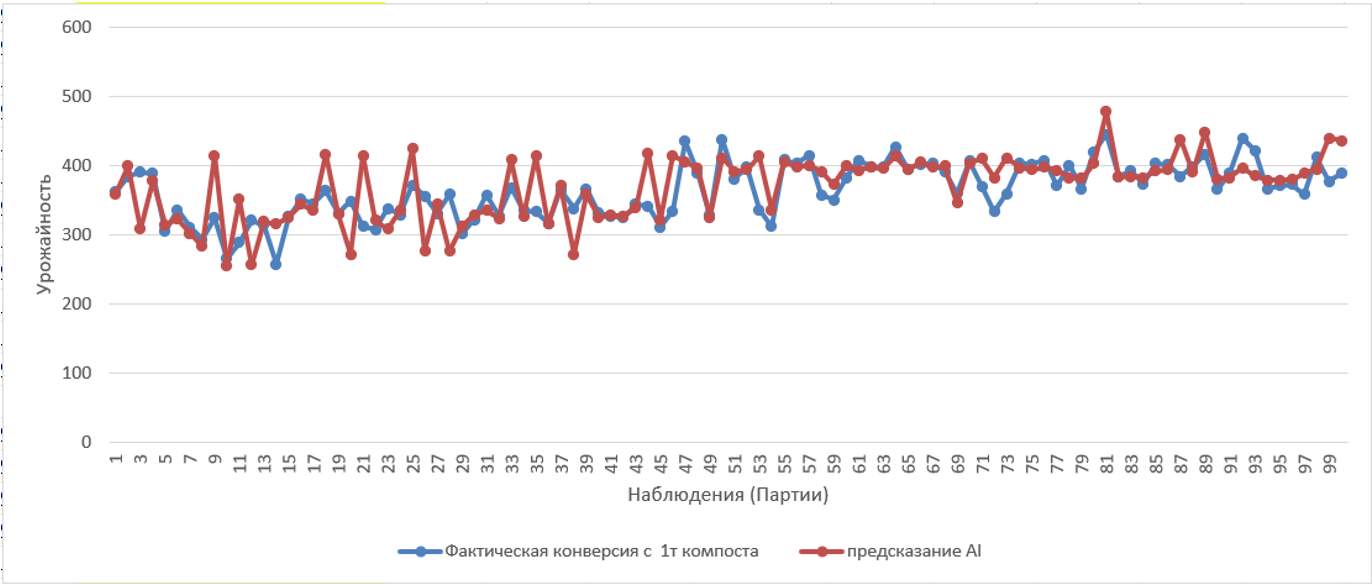
А где здесь деньги?
И любимый вопрос, который появляется после подобного рассказа: где деньги? А деньги в повышении урожайности (конверсии) с тонны компоста на 13% благодаря оптимизации параметров компоста (уровень азота, влажности, зольности, pH и т.д.) и массе компоста, загружаемого в камеру. Теперь клиенту не надо думать, сколько компоста загрузить в камеру: наш алгоритм, опираясь на результаты анализов, строит прогноз и ежедневно присылает клиенту в Telegram рекомендацию по загрузке, где показано, сколько будет собрано гриба в каждом из вариантов. Окончательное решение, сколько загружать, по-прежнему, остается у технолога грибной фермы, т.к. он учитывает еще и реальную производственную ситуацию, и возможности. В том числе понимает, что загруженный объем влияет не только на количество собираемого гриба, но и на его качество и сроки хранения. Это как раз и есть те 13% факторов, которые мы еще пока не оцифровали.
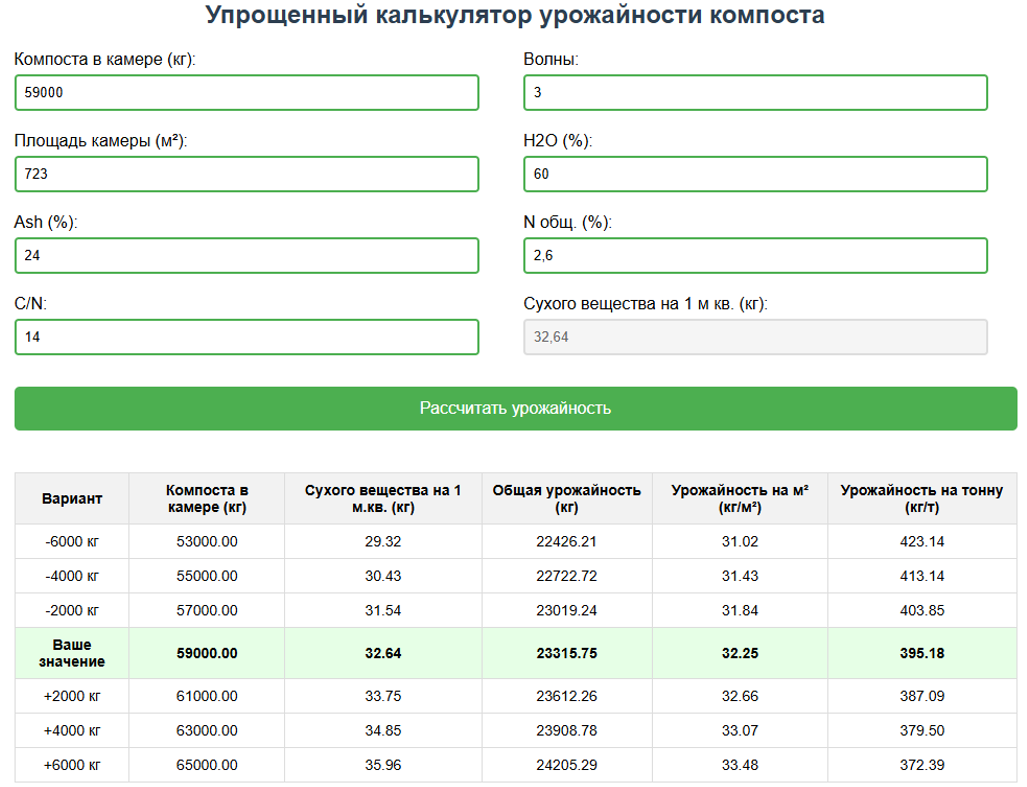
Кроме того, при помощи того же DeepSeek, всего одним развернутым запросом, мы разработали удобный online-калькулятор. Он дает технологам возможность самим оперативно рассчитывать оптимальные параметры компоста и объем его загрузки в камеры, а также контролировать и проверять урожайность по камерам, в которых сбор грибов уже завершен.
Выводы
Подводя итог, можно сказать, что еще два-три года назад такая задача потребовала бы от нас, как минимум, привлечение сторонней компании и разработчиков, возможно, даже покупку специализированного программного обеспечения, а процесс разработки от постановки задачи до тестирования продукта занял бы не один месяц. Сегодня процесс создания первой многофакторной Python-модели на основе RandomForest занял всего два дня, а если нам потребуется создать такой алгоритм для решения другой задачи, то это уже займет меньше часа.
Но процесс разработки не был таким простым, как может показаться, мы столкнулись с целым рядом проблем:
- Требуются базовые знания в программировании. Если в школе или университете вы или кто-то из команды изучали алгоритмы и какой-то из языков программирования и это не было для вас сложностью, тогда вы сможете задавать ИИ-чату правильные вопросы. Хотя порой бывает достаточно скопировать и вставить ошибку, которая появилась после неудачного запуска алгоритма.
- Трудоемкость процесса сбора данных. Для нас было сложно объединить данные с разных учетных систем в одном датасете. Как всегда, поначалу мы все собирали вручную в Excel файле, а уже спустя полгода занялись доработкой ERP-системы и автоматизацией процесса сбора данных.
- Плохое качество данных. Т.к. большинство данных в учетную систему вносили люди, порой они ошибались или вовсе ничего не вносили данные, поэтому в данных появлялись выбросы и пропуски, которые приходилось выявлять и чистить, ведь автоматический алгоритм не всегда срабатывал корректно. Будьте готовы потратить время на это.
- Малый объем данных. Когда только начинается работа с данными непонятно, какие данные нужны и в каком объеме, какой массив данных будет тем самым достаточным для получения качественной модели. Поэтому приходится начинать с малого объема данных, постепенно дополняя их и отслеживая динамику изменения качества прогнозирования.
- Прочие неучтенные факторы. Например, мы не отслеживаем случаи, когда камера была заражена болезнью или гриб не успевали собрать из-за дефицита персонала, а значения урожайности в этих ситуациях сильно снижалась, что делает такие данные нерепрезентативными и вредными для алгоритма.
- Выбор модели и настройка ее параметров. Сегодня существует множество различных моделей и алгоритмов, решающих одинаковые задачи. Какую выбрать, решаете вы. И если перебрать несколько алгоритмов не самая сложная задача, то оптимизация параметров работы выбранного алгоритма уже требует более «творческого» и экспертного подхода, т.к. от того, как вы настроите вашу модель будет зависеть точность ее работы.
- Узкий диапазон работы. Алгоритм может предсказывать лишь в том диапазоне значений, на котором обучился. Например, наши клиенты используют камеры преимущественно 723 и 515 метров квадратных, поэтому для камер другой площади модель не будет корректно работать (мы проверяли на данных зарубежных грибоводов), или если любой другой параметр (влажность, зольность, уровень азота и т.д.) выйдут за границы известного алгоритму, он также может ошибиться. Но алгоритм быстро учится и уже в следующий раз будет работать корректно.
Наш ИИ-алгоритм предсказания урожайности стал лишь первым шагом и открыл перед нами необъятные возможности использования ИИ на производстве. Аналогичным способом мы уже написали и тестируем алгоритм машинного зрения и полноценное Android-приложение, которые оценивают качество зарастания мицелия на компосте, чтобы после накопления достаточного массива данных увязать их в единую систему управления качеством. В наших планах спустя год-два создать своего полноценного цифрового ИИ-технолога, который будет состоять из нескольких ИИ-моделей, контролирующих производственные параметры на всех этапах выпуска продукции, и помогать собирать еще больше грибов стабильно высокого качества.


